



Hadoop and Spark are open-source big data software meant to replace traditional information warehouses. They help organizations harness the power of big data for real-time analytics and business intelligence. When searching for big data solutions, the Hadoop vs. Spark comparison is common.
This article delves into a comparative analysis of the two platforms. Though Spark comes out as the winner, we can’t dismiss Hadoop altogether.
Compare Top Big Data Analytics Software Leaders


What This Article Covers
Hadoop is a distributed computing platform that deploys onsite and in the cloud. It enables building big data systems by provisioning clusters of thousands of nodes. Hadoop is flexible, scalable, fault-tolerant and affordable.
Its components include:
- A distributed file system, HDFS (Hadoop Distributed File System),
- A resource allocator, YARN (Yet Another Resource Negotiator) and
- MapReduce, its processing engine.
Though they’re not part of the original platform, Hadoop adds to its capabilities by working with Apache Hive, Pig and Mahout.
Apache Spark is also a distributed processing framework with feature enhancements that make it a more attractive option. It’s built on the same premise as Hadoop — to spread out workloads over nodes and process them in parallel. It does it faster.
It includes:
- The job scheduling component Spark Core
- The SQL module
- Streaming and structured streaming modules
- A machine learning (ML) library, MLlib
- GraphX and a set of graph analytics APIs
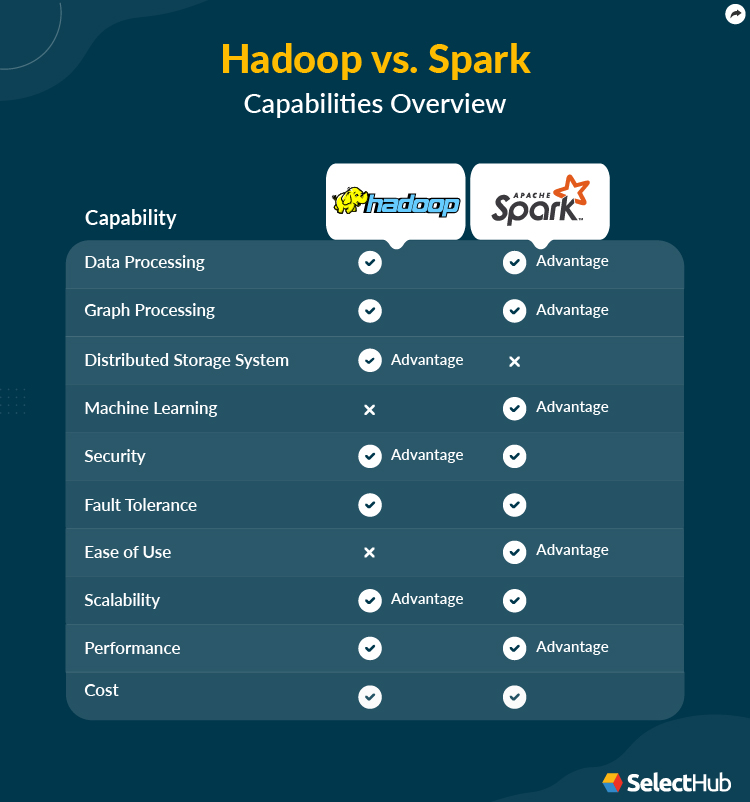
Feature Comparison
Spark was developed at UC Berkeley in 2012 to replace MapReduce. It uses RAM (random access memory) for in-memory analytics, doing away with disks, a MapReduce staple.
What can it do? And where does Hadoop fit in? Let’s find out.

Data Processing
Hadoop is excellent for batch and linear data processing. It’s due to its distributed file system, HDFS, and resource allocator, YARN. MapReduce can process terabytes of data in parallel. It manages several nodes at the same time, storing the data on a disk.
Earlier, MapReduce was the only way to retrieve data from HDFS, but now Hive and Pig provide the same functionality in Hadoop. Hadoop keeps up with the times — some of its components support real-time analytics. But, it’s primarily suited for historical data analysis.
Batch updates are a standard feature of data management platforms, and Apache Spark is no exception. Additionally, it processes live and streaming data with in-memory computation and process optimization. It’s where Spark is an improvement upon Hadoop.
Spark incorporates unstructured data into big data analytics using RDD (resilient distributed datasets) and Dataset APIs. The Dataset API is present in Spark 2.0 and later versions, working over the SQL engine to ensure no data gets left behind.
Dataset APIs help catch errors in the query code at compile time rather than at runtime. They enable custom views, domain-specific operations and superior speeds. Plus, you get complex expressions for filters, maps, aggregations, averages and SQL queries.
High-level abstractions let you create optimized queries and custom views. Spark enables low-level optimization of semi-structured and unstructured datasets, hiding the grunt work at the backend.
Latency
Hadoop has many great features to manage big data, but being fast isn’t one of them.
It delivers high throughput during batch processing, but it isn’t known for real-time processing and analytics.
Part of the issue is the way MapReduce works. Each MapReduce operation includes three steps.
- Read data from HDFS.
- Perform Map and Reduce tasks.
- Write to HDFS.
Even if they don’t use the data, every map-and-reduce operation reads from and writes to a disk. It wastes time and processing power, resulting in sluggish performance and compounding latency issues.
It happens because Hadoop doesn’t allow you to define dependencies beforehand and no performance tuning happens during the process. Performance slows down further when workloads are large and complex.
But, if you don’t mind the delay, MapReduce is great as disk-based storage keeps costs low.
Spark overcomes the latency issue by bypassing the read-write to the disk during transformation tasks, relying on RAM instead. The platform caches intermediate results in memory, which is faster than digging up data from a disk. Processing on par with real time enables live data interactivity.
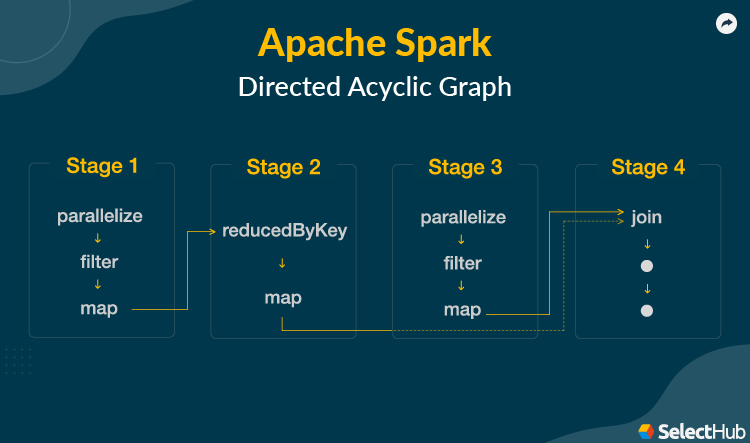
Another improvement on Hadoop is process optimization. Spark creates Directed Acyclic Graphs, or DAGs, for the map and reduce steps. It manages data movement by defining dependencies at the storage and network levels.
Compare Top Big Data Analytics Software Leaders

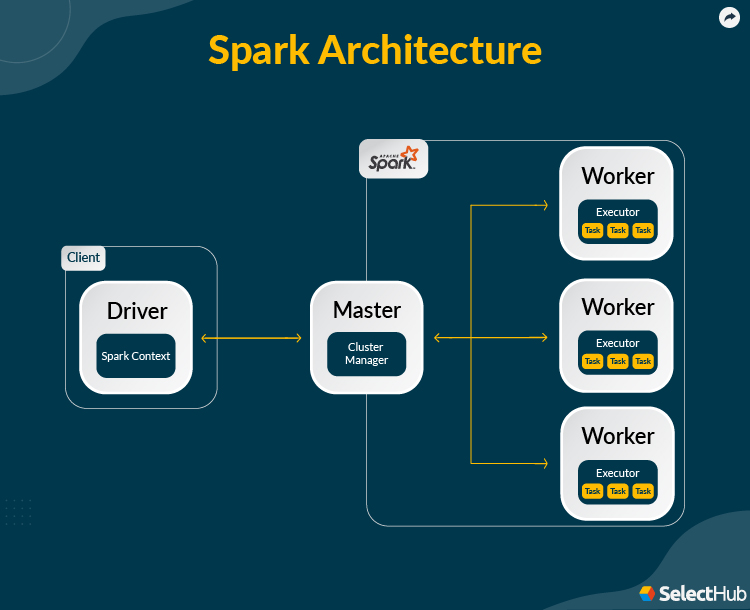
Scheduler and Resource Management
Hadoop doesn’t have a built-in scheduler. It relies on external solutions for cluster management and job scheduling. These include Oozie, FairScheduler and CapacityScheduler.
Spark has a built-in DAG Scheduler and a Block Manager for job scheduling, resource allocation and monitoring. The DAG Scheduler is a public class object that creates an acyclic graph of stages for each job. It divides them further into tasks. It keeps track of generated RDDs and stage outputs and finds the quickest schedule and best locations to execute the job.
The DAG Scheduler efficiently handles failures by submitting old stages for execution in case output files are lost.
It’s assistant, the TaskScheduler, runs the tasks in each stage and reports back. Failure handling is also available at the TaskScheduler level — it retries each task a certain number of times before canceling the whole stage.
Winner: Spark wins with fast data processing and process optimization for live analytics.
Graph Processing
Graph databases are meant to be one-up on relational databases. They speed up data preparation by providing clear query semantics. Nodes and edges describe data relationships, much like graphs.
They can combine big data dimensions like location, time and demographics. Graph processing plays a significant role in artificial neural networks. Managing, storing and querying data through graphs makes identifying relationships and patterns easier.
Hadoop wasn’t designed for graphs and relies on extensions, such as Surfer and GBASE. Surfer uses graph partitioning while adapting to uneven bandwidths. GBASE provides a parallel indexing mechanism for graph operations, saving storage space and accelerating responses.
Spark has a built-in library, GraphX, to view data as graphs. It enables transforming and joining data using RDDs and writing custom graph algorithms. GraphX provides ETL (extract, transform and load), data exploration and graph-based computing within one system. Besides a flexible API, it has a rich collection of user-contributed graph algorithms.
Winner: Spark wins due to its built-in graph library and robust algorithms, while Hadoop relies on third-party tools.
Distributed Storage System
Hadoop HDFS supports distributed data processing by storing large files across networks. It provides high availability and reliability by replicating data across hosts.
Besides HDFS, Hadoop works with any distributed file system that the underlying OS uses. These include Apache Ozone, FTP, Amazon S3 and Windows Azure Storage Blobs file systems.

Spark relies on Hadoop HDFS, as it doesn’t have a distributed file system. Additionally, it can work with Alluxio, MapR File System, Cassandra and OpenStack Swift. The platform can scale with custom file systems.
Spark works with your local file system if needed for development and testing.
Winner: Hadoop wins this one for having its own distributed storage.
Machine Learning
The best use of Hadoop is as a staging layer for managing big data. It’s great at ingesting raw information and storing ETL results for later querying and exploration.
But, it wasn’t designed for ML queries. MapReduce splits them into parallel tasks, creating input-output issues for algorithms that aren’t equipped to handle them.
Hadoop worked with Apache Mahout for clustering, classification and batch-based filtering. As Mahout phases out, Samsara, a Scala-based DSL (domain-specific) language enables writing algorithms.
But, there’s good news. The latest version of Hadoop supports GPUs (graphical processing units), which are faster. YARN can now schedule task runs on GPU, irrespective of the data volume. Another program, TensorFlowonSpark (TFS), supports deep learning models that run on Hadoop and Spark.
Spark supports iterative in-memory computations, thanks to its algorithm-rich machine learning library, MLlib, which is available in Java, Scala, Python and R. The library includes classification, regression, pipeline construction, persistence and evaluation algorithms. It enables hyperparameter tuning for building machine learning pipelines.
Winner: Spark is the superior platform with its built-in ML algorithm library, though Hadoop supports machine learning with partner integrations.
Security
Hadoop uses many authentication and access control methods. These include Kerberos authentication, LDAP (Lightweight Directory Access Protocol) and inter-node encryption. Standard file permissions on HDFS and Service Level Authorization are others.
Security is off by default, which exposes you to risk if you don’t act right away. You can opt for authentication via shared secret or event logging. Spark relies on integration with Hadoop to achieve the required security level.
Winner: Hadoop scores here as the superior security provider.
Fault Tolerance
Hadoop keeps copies of data across nodes as a fail-safe mechanism. It helps the platform create missing blocks from other locations if an issue occurs. The master node keeps track of all slave nodes and if a node doesn’t respond, assigns pending tasks to others.
Fault tolerance is another feather in Spark’s cap, and it relies on RDD blocks for the purpose. The system keeps a track of the RDD and DAG workflows and can rebuild data if needed.
Winner: It’s a tie as both products have robust fail-safe protocols in place.
Ease of Use
Writing MapReduce pipelines is a complex and lengthy process. Though Hadoop has a Java base, its code isn’t easy to learn and requires specialized training. Dealing with low-level APIs is time-consuming and tedious and interactive mode is available only with Hive and Pig integrations.
Spark has interactivity built in, enabling quicker adoption. Its code is compact and development is a breeze with Scala, Python, Java and Spark SQL APIs. Abstractions are possible with over 80 high-level operators.
Winner: Spark wins this one with user-friendly APIs and interactivity out of the box.
Scalability
Hadoop scales when workloads increase by adding thousands of nodes and disks. HDFS plays a big role in its scalability by efficiently managing big data.
Spark can find it challenging to scale as it needs HDFS, which is possible only if you’re using Spark on top of Hadoop. Also, RAM availability is limited in clusters.
Winner: Hadoop wins this one, thanks to its infinite scalability.
Performance
The lack of workflow optimization in MapReduce affects Hadoop’s performance in a big way. Working with low-level APIs is tedious, cumbersome and eats into your time. Your installed software and business systems also impact Hadoop’s functioning.
RAM makes Spark’s data processing faster, allowing you to explore and analyze data as you get it. Real-time insights include data from machine learning algorithms, marketing campaigns and transactional systems. It includes streaming data from IoT (Internet of Things) sensors, chatbots, social media sites and apps.
Spark is highly performant for processing batch and streaming data. In-memory computing and a super-efficient task scheduler optimize query runs, executing many tasks in parallel and producing results within seconds.
Winner: Spark wins for batch and streaming data analysis.
Cost
Both Hadoop and Spark are open source and free. The difference lies in hardware — Hadoop relies on disk storage while Spark runs on RAM. Real-time processing is worth the cost of RAM.
Factor in infrastructure, development and maintenance when calculating the total cost of ownership.
Winner: In this Hadoop vs. Spark comparison, it’s a tie as Spark’s support for real-time analytics justifies the cost.
The Verdict
Of the ten features, Spark ranks as the clear winner by leading for five. These include data and graph processing, machine learning, ease of use and performance. Hadoop wins for three functionalities – a distributed file system, security and scalability. Both products tie for fault tolerance and cost.
FAQs
What are the advantages and disadvantages of Hadoop?
Where it scores:
- Fast batch processing.
- Hadoop Distributed File System.
- Authentication and access control.
- Fault tolerance.
- Scalability.
- Inexpensive disk storage.
Where it lags:
- Not cost effective for small data environments.
- Not suitable for real-time analytics.
- Lacks an intuitive programming interface out of the box.
- High latency computing architecture.
- Not easy to use.
- Lacks performance tuning capabilities.
- Doesn’t have a built-in task scheduler.
- Doesn’t provide graph processing out of the box.
- Lacks native machine learning support.
What are the advantages and disadvantages of Spark?
Where it shines:
- Built-in support for Scala, Spark SQL, Java, R and Python. It relies on third parties to enable programming with .NET CLR and Julia.
- Live data interactivity and real-time analytics.
- Low-latency computing architecture.
- Enables performance optimization with DAG.
- In-memory storage and processing save time.
- Includes a task scheduler.
- Graph processing out of the box.
- Has a built-in machine learning library.
- Fault tolerance.
Where it doesn’t:
- Lack of a distributed file system.
- Security is off by default.
- Limited in the amount of RAM it can access in the cluster.
Can you use Hadoop and Spark together?
Yes. Many organizations combine Hadoop and Spark for big data processing and analytics, using their respective strengths to drive the pipeline. Hadoop is great at batch processing data uploads, transformations and storage. It hands over the data to Spark for real-time processing and analytics.
When should you use Hadoop and when should you use Spark?
Hadoop is a great choice for managing workload-intensive operations that don’t need instant turnarounds. Maintaining a structured store of customer information is one such example. In such cases, you can go it alone with Hadoop.
Spark’s fast processing power comes in handy when you want instant results. Consider deploying Spark with Hadoop if you want real-time analytics and machine learning.
Next Steps
Want to see how Hadoop and Spark compare against other products? Our free comparison report breaks it down for you. Whether you opt for one of these or another big data processing solution, do your due diligence before deciding.


Create a Requirements Checklist
List your business needs or get our ready-to-go template pre-filled with industry-standard requirements. Ask yourself these questions.
- What’s not working with your current system? Which gaps do you need to fill with the new solution?
- Who are the users? What are their skill levels?
- What are your infrastructure’s strengths and weaknesses?
- Which is your preferred deployment method?
- Do you need instant turnarounds and real-time analytics? How important is low latency to your domain?
- What are your storage and data processing requirements?
This list is merely suggestive. Add more questions as you go along to get an in-depth insight into the products you’re considering.
Get Stakeholder Approval
Verify your requirements checklist by discussing with stakeholders and teams that’ll use the software. Collaborative software is an excellent way to record everyone’s feedback. Convert your requirements into questions and send them to potential vendors.
Rank Features and Vendors
Review vendor responses with senior management to create a shortlist. Rank vendors based on how likely they are to address your business needs. Have team members score features based on their individual needs.
Summarize and Formalize
Collate the results into a formal report with features in descending order of priority and share with everyone for review. It’ll give you a clear idea of the must-have and nice-to-have features. Compare this report with what vendors are offering to sift out the ones that can address your requirements.
Finalize the Vendor
Reach out to vendors, starting at the top of the list. Meet them to convey your expectations and learn about their products and services. Do your due diligence before deciding and signing on the dotted line.
Wrapping Up
Software selection deserves time and thorough research. Additionally, getting a feel of how the product works with your infrastructure is essential. Ask potential vendors if they offer a free trial, and talk to industry colleagues who’ve tried the product for a first-hand account of its performance.
Still find it overwhelming to get started? Follow our nine-step Lean Selection Methodology to get the best-fit system.
Which product stands out to you in our Hadoop vs. Spark comparison? Let us know in the comments.
Top Competitors













